
Reactive Programing(1) – 리액티브 프로그래밍 개념잡기
Reactive Programing(2) – Reactive Operator
Reactive Programing(3) – Reactive Operator
Reactive Programing(4) – Scheduler
Reactive Programing(5) – 안드로이드에서의 RxJava 활용
Reactive Operators(리액티브 연산자)
리액티브 연산자의 소개
링크 : http://reactivex.io/documentation/operators
리액티브 연산자는 자바의 관점에서 보면 메소드이지만, 함수형 프로그래밍의 원리에 따르면 리액티브 연산자는 Side Effect가 없는 순수 함수 입니다. RxJava에서는 함수라고도 부릅니다.
함수의 종류는 400개가 넘습니다.
모든 함수를 다 짚고 넘어가기는 힘이 들고 의미가 무엇인지만 알면 쉽게 이해 할 수 있으므로 가장 많이 쓰는 함수 위주로 설명하겠습니다.
1. map() 함수
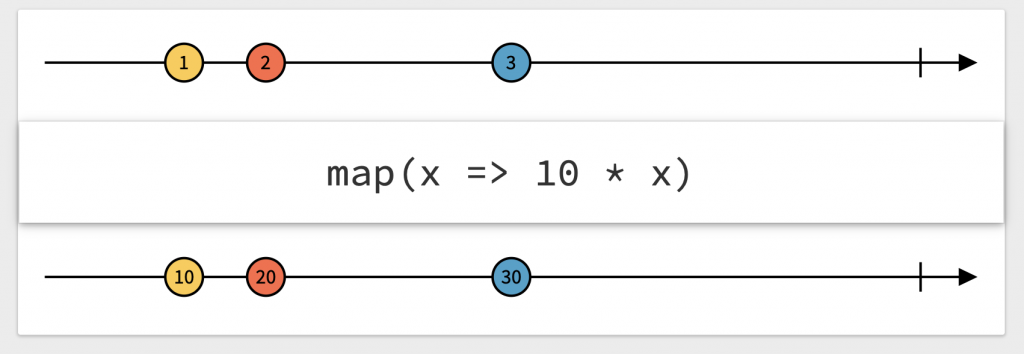
map 함수는 입력된 데이터를 함수에 넣어서 원하는 값으로 변환하는 함수 입니다. int를 String 으로 변환 할 수도 있고 다른 객체로 변환할 수도 있습니다.
위의 마블 다이어그램을 RxKotlin으로 변환하면 아래와 같습니다.
val array = arrayOf(1, 2, 3)
array.toObservable().map {
it * 10
}.subscribe{
println(it)
}
결과
10
20
30
1,2,3이 들어있는 배열을 Observable객체로 변환하고 map 연산자를 통해 각 값에 10을 곱해주고 있습니다.
2. flatMap() 함수
map함수를 발전시킨 형태로 결과가 Observable로 나온다는 것이 다릅니다.
그렇기 때문에 1:N 형태로 데이터가 나올 수 있습니다.

val names = arrayOf("Charles", "Runa", "David")
val source = names.toObservable().flatMap { Observable.just("${it}1", "${it}2") }
source.subscribe{
println(it)
}
결과
Charles1
Charles2
Runa1
Runa2
David1
David2
각 사람의 이름을 받아 두개씩 출력하는 예제 입니다. 하나의 데이터를 Observable만들고 가공된 두개의 데이터를 다시 넣는 모습을 볼 수 있습니다.
RxJava에서 여러 개의 데이터를 발행하는 방법은 Observable밖에 없습니다.
3. filter
필터라는 말그대로 Observable에서 원하는 데이터만 걸러내는 역할을 합니다.
val originalData = Observable.just(2, 30, 22, 5, 60, 1)
val filteredData = originalData.filter { x ->
return@filter x > 10
}
filteredData.subscribe {
println(it)
}
결과
30
22
60
filter 라는 함수를 통해 데이터를 걸러줍니다. filter에 들어갈 인자값이 Predicate인데 boolean을 리턴하는 특수한 함수형 인터페이스입니다. 반환값이 false면 걸러지고 true면 그대로 통과 합니다.
필터와 비슷한 기능을 하는 함수들
- first(기본값) : 첫번째값을 걸러줌, 없으면 기본값
- last(기본값) : 마지막값을 걸러줌, 없으면 기본값
- take(N) : N개의 값만큼 걸러줌
- takeLast(N) : 마지막으로부터 N개 걸러줌
- skip(N) : N개만큼 건너뛰고 걸러줌
- skipLast(N) : 마지막으로부터 N개만큼 값을 건너뛰고 걸러줌
4. reduce 함수
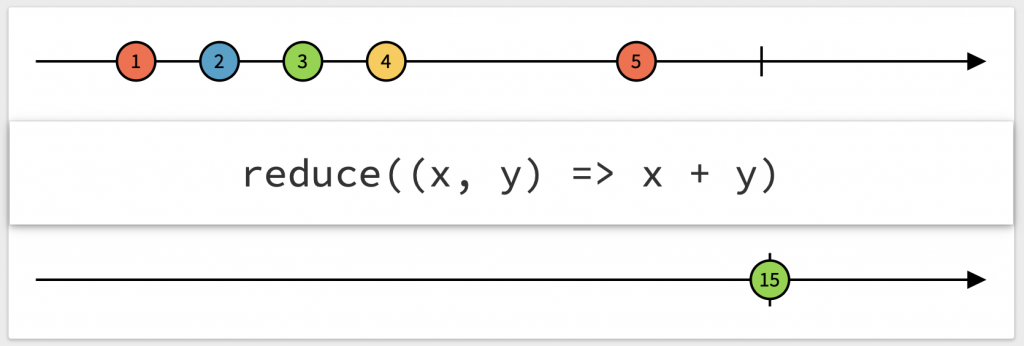
reduce는 발행한 데이터를 합칠때 사용합니다.
(저는 처음에 reduce라는 함수명을 보고 데이터를 빼는 걸 상상했는데 아니였습니다.)
BiFunction<T,T,T>을 인자로 가지며 함수의 인자와 리턴타입이 모두 같아야합니다.
마찬가지로 람다식으로 표현가능합니다.
Observable.just("A", "B", "C").reduce { t1: String, t2: String ->
t1+t2
}.subscribe {
println(it)
}
결과 :
ABC
처리 순서는 다음과 같습니다.
0번째 사이클 : t1 = A, t2 = B. t1과 t2 문자열을 합쳤으므로 다음. t1은 AB가 될것입니다.
1번째 사이클 : t1 = AB, t2 = C. AB와 C 문자열을 합치므로 ABC를 최종적으로 리턴합니다.
들어오는 데이터를 1개씩 모아모아 최종결과를 만들어야할 때 사용합니다.
데이터 쿼리 예제
지금까지 배운 내용으로 데이터를 쿼리하는 예제를 만들어보았습니다.
제조사별 휴대폰 모델에 따른 매출규모 리스트에서
특정 휴대폰 매출을 합산하는 예시 입니다.
val sales = ArrayList<Pair<String, Int>>().apply {
add(Pair("Galaxy Note8", 2500))
add(Pair("G7", 2500))
add(Pair("Galaxy S9", 1600))
add(Pair("iPhone X", 800))
}//모델별 매출 리스트
val galaxySales = Observable.fromIterable(sales) // 리스트를 옵저버블로 변환
.filter { t: Pair<String, Int> ->. //Galaxy모델만 필터링. Note8, S9
t.first.contains("Galaxy", true)
}
.map { t ->
t.second //필터링 된 Pair객체를 매출로 변환
}
.reduce { t1: Int, t2: Int ->
t1 + t2 // 모든 매출규모를 합산
}
galaxySales.subscribe {
println("total=${it}")
}
결과:
total = 4100
리액티브 연산자의 분류
| 스케쥴러 | 설명 |
|---|---|
| newThread() | 새로운 스레드 생성 |
| single() | 단일 스레드 생성 후 사용 |
| computation() | 계산용 스레드 |
| io() | 네트워크, 파일 입출력 스레드 |
| trampoline() | 현제 스레드에 대기행렬 생성 |
리액티브 연산자의 활용
생성 연산자
생성 연산자는 데이터 흐름을 만들며, 간단하게 말해서 Observable객체 등을 생성합니다.
1.interval() 함수
interval()은 일정한 간격을 가지고 데이터를 발행하거나 초기 지연값을 가지고 일정한 간격으로 데이터를 발행할 때 쓰입니다. 0부터 주어진 시간 간격을 가지고 1씩 증가합니다.
ComputationScheduler에서 실행됩니다. 별도의 스레드에서 동작한다고 생각하면 됩니다.
Observable.interval(100,TimeUnit.MILLISECONDS).subscribe {
println(it)
}
Thread.sleep(1000)
결과:
1
2
..
8
9
2. timer() 함수
일정 시간 지난후 한개의 데이터를 발행하고 끝납니다. timer도 Computation Scheduler에서 동작합니다.

println(System.currentTimeMillis())
Observable.timer(1000, TimeUnit.MILLISECONDS)
.subscribe {
println(System.currentTimeMillis())
}
Thread.sleep(2000)
결과:
1524019410453
1524019411530
3. range() 함수
2개( n, m)의 인자로 객체를 생성하고, n부터 m개까지 1씩 순차적으로 증가하는 Integer를 발행합니다. 별도의 Scheduler가 없습니다. 그러므로 for,while 같은 반복문을 대체 할 수 있습니다.

@Test fun rangeTest(){
Observable.range(5,5).subscribe {
println(it)
}
}
결과:
5
6
7
8
9
4. intervalRange() 함수
interval과 range를 합친 함수. Computation Scheduler를 사용합니다.

Observable.intervalRange(5,5,0,100, TimeUnit.MILLISECONDS)
.subscribe {
println(it)
}
Thread.sleep(1000)
결과:
5
6
7
8
9
인자값을 살펴보자면
첫번째 인자 : 시작값(n)
두번째 인자 : 카운트(m)
세번째 인자 : 초기 지연 값
네번째 인자 : 실행주기
다섯번째 인자 : 시간 단위
100ms마다 데이터를 발행하고 있습니다. 카운트가 5이므로 , 100ms * 5 =500ms = 0.5초만 실행되어집니다.
interval()함수로 intervalRange를 만들수도 있습니다.
Observable.interval(100, TimeUnit.MILLISECONDS)
.map {
it + 5
}
.take(5)
.subscribe{
println(it)
}
Thread.sleep(1000)
결과는 같습니다.
5. defer()함수
Observable을 subscribe 할 때 생성하는 연산자 입니다.
다시 말하자면 Observable의 생성 자체를 지연시키기 때문에 데이터의 흐름을 구독자가 subscribe()함수를 호출하기전까지 미룰수 있습니다.

val colors = arrayListOf("Red", "Green", "Blue").iterator()
val supplier = Callable {
if (colors.hasNext()) {
val color = colors.next()
Observable.just(
"$color Circle",
"$color Rectangle",
"$color Pentagon")
} else {
Observable.empty()
}
}
val source = Observable.defer(supplier)
source.subscribe {
println("#1:$it")
}
source.subscribe {
println("#2:$it")
}
결과:
#1:Red Circle
#1:Red Rectangle
#1:Red Pentagon
#2:Green Circle
#2:Green Rectangle
#2:Green Pentagon
colors는 도형의 색상을 담은 리스트이며 별도의 인덱스 없이 데이터를 순차적으로 접근하기위해 iterator()를 썼습니다. Callable객체를 만들때는 colors에 접근해 현재 색상을 가져와서 도형 3개를 갖는 Observable을 동적으로 생성하도록 했습니다. 이렇게 만들어진 Callabler객체를 defer에 넣고 구독자를 추가하면 구독자를 추가할때 Observable을 만들어서 데이터를 발행하게 되므로 색깔별로 그리고 순차적으로 도형을 만들어 발행하게 됩니다.
6. Repeat() 함수
단순히 반복실행 하는 입니다. 반복할 횟수를 정할수도 있고 정하지 않으면 무한히 실행됩니다.

Observable.just("Red", "Blue", "Green")
.repeat(3)
.subscribe({ next ->
println(next)
}, { error ->
println(error)
}, {
println("finished")
})
결과:
Red
Blue
Green
Red
Blue
Green
Red
Blue
Green
finished
변환 연산자
1. concatMap() 함수
flatMap과 비슷하지만 concatMap의 다른점은 먼저 들어온 데이터를 처리하는 도중에 새로운 데이터가 끼어들어도 먼저 들어온 데이터 순서대로 처리해서 결과를 낼 수 있도록 보장해주는 함수 입니다.

- concatMap을 활용했을때
Observable.interval(100L, TimeUnit.MILLISECONDS)
.map {
it.toInt()
}
.map {
colors[it]
}
.take(colors.size.toLong())
.concatMap { color ->
Observable.interval(200L, TimeUnit.MILLISECONDS)
.map { "${color} Diamond" }
.take(2)
}
.subscribe {
println(it)
}
Thread.sleep(2000)
결과:
Red Diamond
Red Diamond
Blue Diamond
Blue Diamond
Green Diamond
Green Diamond
- flatMap을 활용했을 때
Observable.interval(100L, TimeUnit.MILLISECONDS)
.map {
it.toInt()
}
.map {
colors[it]
}
.take(colors.size.toLong())
.flatMap { color ->
Observable.interval(200L, TimeUnit.MILLISECONDS)
.map {
"${color} Diamond"
}
.take(2)
}
.subscribe {
println(it)
}
Thread.sleep(2000)
결과 :
Red Diamond
Blue Diamond
Green Diamond
Red Diamond
Blue Diamond
Green Diamond
두 샘플 코드에서 다른점은 flatMap을 쓰느냐 concatMap을 쓰느냐입니다.
concatMap은 앞서 말했듯이 순서를 보장하지만 flatMap은 뒤죽박죽 섞이고 있습니다. interleaving(끼어들기)를 허용하고 있기 때문입니다.
위의 코드에서 concatMap의 경우에는 interleaving을 허용하지 않기 때문에 200ms씩 충분히 기다리면서 데이터를 발행하기때문에 flatMap보다 실행시간이 더 깁니다.
flatMap의 경우에는 interleaving을 허용하기 때문에 200ms기다리는 도중 100ms 간격으로 새로운 데이터가 끼어들어 순서가 뒤죽박죽 되지만 총실행시간은 concatMap보다 짧습니다.
2. switchMap() 함수
concatMap 함수가 인터리빙이 발생할 수 있는 상황에서도 동작 순서를 보장해주는 반면
switchMap은 함수의 순서를 보장하기 위해서 기존작업을 바로 중단합니다.

- 위의 contcatMap 샘플코드와 비교했을 때의 switchMap
val colors = listOf("Red", "Blue", "Green")
Observable.interval(100L, TimeUnit.MILLISECONDS)
.map {
it.toInt()
}
.map {
colors[it]
}
.take(colors.size.toLong())
.switchMap { color ->
Observable.interval(200L, TimeUnit.MILLISECONDS)
.map {
"${color} Diamond"
}
.take(2)
}
.subscribe {
println(it)
}
Thread.sleep(2000)
결과:
Green Diamond
Green Diamond
첫 Observable에서 Red가 발행되고 switchMap내부의 Observable에서 Diamond로 변하기까지는 200ms 가 걸린다. 근데 여기서 다시 Blue가 100ms 이내에 발행되므로 Red가 Diamond로 변하기도 전에 Blue데이터가 발행되는 셈이다. 그러면 Red는 무시되고 다시 Blue에대한 수행만 처리한다. 하지만 Green이 100ms 있다가 또 발행되면서 Blue도 무시가 되고 그린만 다이아몬드로 변한다.
이처럼 기존작업을 중단하더라도 마지막 데이터의 처리는 보장하는것이 switchMap의 특징이다.
예제코드를 하나 더 보도록 하자.
- switchMap의 마블 다이어그램을 코드로 했을 때
Observable.create<String> { e ->
e.onNext("Red")
Thread.sleep(250)
e.onNext("Green")
Thread.sleep(50)
e.onNext("Blue")
}.switchMap { color ->
Observable.interval(0L,100L, TimeUnit.MILLISECONDS)
.map {
when (it) {
0L -> return@map "$color <>" //다이아몬드 발행
1L -> return@map "$color []" //사각형 발행
else -> return@map null
}
}
.take(2)
}.subscribe {
println(it)
}
Thread.sleep(2000)
결과
Red <>
Red []
Green <>
Blue <>
Blue []
먼저 데이터의 흐름을 직접 컨트롤 하기 위해 create메소드를 썼습니다.
Red를 발행하고 250ms 를 쉽니다. 그러는동안 switchMap내부의 Observable에서는 초기값 0ms , 인터벌 100ms 를 가지고 데이터를 발행하기 시작합니다. 2개만 발행하므로 약 100ms정도 소요 되며 250ms 내에 데이터 발행이 끝날것입니다. 그렇기 때문에 Red의 경우 다이아몬드, 사각형이 모두 발행됩니다.
뒤이어 250ms가 지나고 Green이 발행됩니다.
바로 Green 다이아몬드를 발행하고 다음 Green 사각형을 발행하려고 하나 50ms 뒤에 Blue가 발행되므로 Green 사각형은 무시되어집니다.
Blue는 정상적으로 다이아몬드와 사각형이 발행됩니다.
3. groupBy() 함수
groupBy함수를 쓰면 데이터가 들어있는 Observable객체를 특정 그룹Observable로 재정의할 수 있습니다.
발행된 GroupObservable을 이용하여 데이터를 그룹별로 처리 할 수 있습니다.

- groupBy 마블다이어그램을 코드로 옮기면
val list = listOf(
"Circle Pink",
"Circle Cyan",
"Triangle Yellow",
"Circle Yellow",
"Triangle Pink",
"Triangle Cyan"
)
val source = list.toObservable().groupBy {
if (it.contains("Circle")) {
"C"
} else if (it.contains("Triangle")) {
"T"
} else {
"None"
}
}
source.subscribe { group: GroupedObservable<String, String>? ->
group?.subscribe {
println("${group.key}:$it")
}
}
결과:
C:Circle Pink
C:Circle Cyan
T:Triangle Yellow
C:Circle Yellow
T:Triangle Pink
T:Triangle Cyan
도형 리스트를 Observable로 만듭니다. groupBy함수를 통해 어떻게 그룹을 지을건지 결정합니다. 위의 샘플코드의 경우에는 원은 C로 , 삼각형은 T로 key를 정의헀습니다. 그룹핑이 끝나면 구독자를 지정 합니다. 이때 람다식에 들어오는 인자는 GroupedObservable이고 이 객체를 통해 group의 key명을 알 수 있습니다. 이 객체의 내부데이터를 또 발행하기 위해 그룹객체에 또 구독자를 지정합니다.
- 랜덤한 숫자들 짝수, 홀수 그룹 짓기
val r = Random()
Observable.range(0, 10).map {
r.nextInt(100)
}.groupBy { number ->
if (number % 2 == 0) {
"even"
} else {
"odd"
}
}.subscribe { grouped: GroupedObservable<String, Int>? ->
grouped?.subscribe { value: Int? ->
println("${grouped.key}:$value")
}
}
4. scan() 함수
reduce와 비슷하나 데이터를 발행할때마다 그에 맞는 중간결과 및 최종결과를 구독자에게 발행합니다.

Observable.just("Red", "Green", "Blue").scan { color1: String, color2: String ->
"$color1 $color2"
}.subscribe {
println(it)
}
결과:
Red
Red Green
Red Green Blue

{kind=link}
0개의 댓글